对于互联网的大量信息,选择合理的公平和有序搜索结果是当今的一个大问题。Nutch具有开放式结果排序算法和大型分布式搜索引擎所需的基本功能。Nutch研究在我们对搜索引擎的深入理解中起着主导作用。[关键词]荷兰搜索引擎21世纪是互联网时代,随着科技的发展,互联网已经进入了大众的日常生活。而,面对如此多的信息,我们迷失了方向。Nutch的诞生极大地帮助我们从大量信息中提取相对公平和客观的信息。Nutch有一些基本的搜索引擎功能,并有自己的特殊算法来评估网页的价值,努力为用户提供最合理的搜索结果。于Nutch Nutch是一个用Java实现的开源搜索引擎。
然市场上已经有几个成熟的搜索引擎,但我们对Nutch的研究并没有受到打扰,主要原因如下:透明度Nutch是一个开源软件,所以任何开发人员都可以在里面看到它。
序算法。此,Nutch更适合对结果公平性的相对公平的质询。
入了解搜索引擎Nutch的研究使我们能够更好地理解大型分布式搜索引擎的运作。
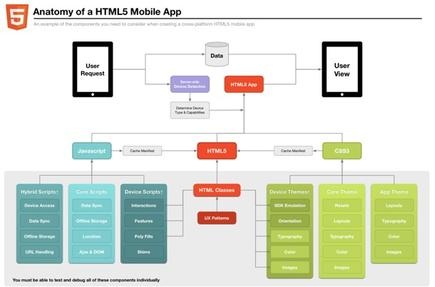
Nutch系统结构和工作流Nutch的核心组件主要包括爬虫,索引和搜索。架构如图1所示.Nutch通过Web-DB,LinkDB,Segetments和Index的数据结构支持数据.Nutch的完整工作流程可分为几个步骤:创建URL base,将基本URL添加到crawlDB数据库,整个Web爬网过程URL开始爬网,最多达到指定数量的爬网层,创建爬网列表,执行扫描,获取有关Web内容的信息,更新数据库,重复步骤3到5到预定义的扫描深度。每个段生成索引,从冗余Web页面和URL中删除这些页面,将小索引合并到大型索引中,使用用户端口查询,将用户请求转换为Lucene查询,并返回结果。
Nutch Nutch的技术分析主要由Crawler和Searcher组成。Crawler从Internet搜索网页,并为每个网页创建特定索引。索器使用机器人创建的索引来搜索基于用户搜索的关键字的结果。Crawler和研究员之间的接口是一个索引。索Crawler Crawler重点关注其运行过程的格式和含义以及包含的数据文件。据文件主要包括Web数据库,分段和索引三种类型。虫的详细工作流程如下:创建WebDB后,“生成/浏览/更新”循环以基本URL开头。此循环完成时,资源管理器将根据扫描期间生成的段创建索引。删除URL之前,每个段的索引是独立的。后,每个单独的段索引合并为最终索引索引。Nutch对网页的去噪主要涉及删除不必要的信息,如广告标签,并从网页中获取尽可能多的内容。于网页,去噪处理包括以下步骤:根据“By”标识,“last last”等字样从标签中提取文本主题。
取作者,更改日期和其他信息。用HtmlParse删除各种脚本,图像和其他信息,并获取仅包含链接和文本的字符串。用网页的一般特征从导航栏中删除文本,并删除由“<”和“>”标识的所有链接文本。除版权通知信息。上述四种方法之后,基本上可以删除相对未开发的信息,例如广告,导航信息,客户代码等,这对于获得相对好的网页内容非常有用。Nutch Benchmarking通过研究,我们将Nutch与当前的开源搜索引擎进行比较,
宁波seo包括Heritris,WCT和Web-Harvest。Nutch提供网页挖掘,分析和理解,连接数据库创建,网页评估,Lucene索引和日志记录。搜索界面。Heritrix提供丰富的分析参数,完整而完整的网站内容副本。WCT可以获取目标站点的获取授权,获取计划和资源描述等信息。Web-Harvest可以使用用户指定的网页作为分析的起始页面,并通过规则表达式语法进行多级分析,以形成XML文档。图2所示,Nutch具有显着的比较优势。
勘探过程中,Nutch对需要大存储空间但价值低的信息有更高的好处。Nutch的改进领域一直在由团队进行研究和测试,该团队主要发现了以下影响其性能的问题:等待时间严格。N每个页面等待时间是Nutch-default.xml配置文件预定义的固定值:http.max.delays和fetcher.server.delay,这将导致在不同网络情况下相当大的时间损失。理沮丧的链接网站是不够的Nutch没有详细监督错误的网络链接的探索。
个网站可能会被关闭或域名被更改,但是其他网站上仍然有链接。果您通过Nutch找到并且您逐个测试它,您将失去大量时间和网络资源。论由于透明的查询算法,Nutch的搜索结果对用户来说是诚实的。是,Nutch在这些商用引擎(如谷歌和百度)之间仍然存在巨大差距,希望开发商能够将自己的力量用于Nutch的开发和改进。
者简介来自甘肃省庆阳市的徐生(1995-)。现在是新疆大学的本科生。件工程。者单位新疆维吾尔自治区乌鲁木齐新疆大学83万"
本文转载自
宁波seowww.leseo.net
补充词条:
宁波谷歌优化
宁波网络seo
宁波seo排名
宁波网站排名优化
宁波seo外包


