在大数据时代,在线信息量迅速增长,智能搜索系统可以帮助用户快速定位查询资源。文重点介绍搜索引擎原理,并解释如何使用Lucene和Ajax实现智能搜索。细分析了Lucene的搜索引擎模型,数据库设计和模块设计,并研究了Lucene.net搜索引擎原理的关键问题。键词:Lucene,异步更新,Ajax,计算机技术搜索引擎和互联网技术的快速发展,导致互联网泡沫迅速扩大,对搜索结果的准确性构成巨大挑战。在如此庞大而复杂的网络环境中提取对您有用的信息,您必须使用搜索引擎来补充它。建一个根据您的需求量身定制并可与Lucene.net一起使用的搜索引擎非常方便。文档描述了相对简单的中文智能搜索引擎开发过程的关键问题,并研究了当前的研究和新的编程技术。

午开发环境,智能搜索引擎Microsoft提供的.NET是一个用于Web服务的开发平台,包括.NET企业服务器,基础架构和服务Web和其他组件可以提供更完整的解决方案。此,在该系统的开发中,采用ASRNET作为该设计的开发工具。们选择Microsoft .NET作为开发平台。时,选择C#作为开发语言,选择Microsoft Visum Studio.NET 2005作为开发平台,选择Microsoft SQL Server 2005作为主数据库。Ajax程序用于优化搜索引擎系统以部分更新浏览器页面。为一个功能强大的信息检索工具库,Lucene可以为搜索引擎应用程序提供工具包,由Lunene.net补充,集成到程序中以提供关键字搜索功能。
于程序,也可以用于索引文档。Lucene.net构建搜索引擎原理搜索引擎工作流程分为三个步骤:第一步是分析网页,第二步是创建索引数据库,第三步是搜索索引数据库。全文搜索中,程序中预定义了属于多个地址的网站,程序的Spider程序模块开始从预定义的网站收集网页元素并跟随链接在网站上(或这些)。过并完成整个过程。
Spider收集的Web页面必须首先运行程序分析过程。据预定算法执行操作后,将结果添加到索引数据库中。
户通常每天执行的全文搜索引擎只有一个用户搜索界面。作过程如下:首先根据用户检索的内容检索关键字,然后搜索引擎根据关键字查找数据库中的所有关联网页。后显示根据预定义规则获得的网页列表的结果。世。于存在各种搜索引擎,它们的预定义规则和索引数据库是不同的。此,用户查看的最终搜索结果是不同的。于预定义的初始网页,Spider程序可以自动访问网络,访问页面,并从页面中提取所有URL。外,Spider程序还可以访问与URL对应的其他页面,继续从辅助页面提取URL,最后重复该过程,直到程序定义的级别数量结束。止。Spider程序探索的所有页面都由分析索引程序进行分析。程序检索关于网页的信息,包括网页的URL,
宁波网站优化网页内容使用的编码类型,以及网页代码头中包含的网站。系列信息,如关键字。后,基于提取的关联信息,根据预定义的排序算法构造和分类网页索引数据库。
此,当用户搜索时,搜索程序检测用户输入的关键字,然后基于关键字搜索服务器。台索引数据库检索与堆栈中该关键字对应的所有相关网页。后,页面生成系统调用包含查询的网页的堆栈,从堆栈中提取网页地址,以及在页面中包含突出显示的关键字部分的页面摘要内容,并将其呈现给页面。户。于每个搜索引擎的搜索索引数据库不同并且搜索引擎只能搜索存储在数据库中的内容,因此用户搜索不同的搜索引擎和搜索引擎。
果不会完全一样。
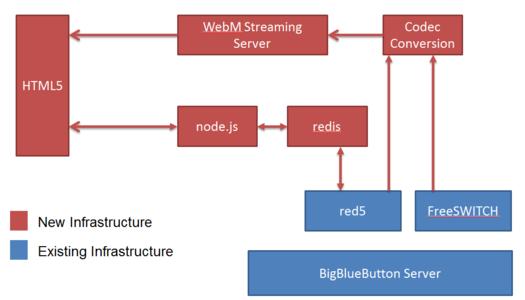
索引擎设计和实现搜索引擎模型包括爬网程序,索引生成,查询和系统配置。
器人包括:网络分析模块,网页减肥模块和机器人维护模块。引生成包括:基于文本文件的索引,基于数据库的索引。询部分有A] ax,后台处理和前端接口模块,如图1所示。据库设计本主题包含一个用于存储分析信息的网页,如表1.模块的设计和实现模型根据功能分为三个部分:解析器,网页部分的解析器,构建索引部分的第二步从数据库和第三步查询封面的部分。一个或多个初始网页开始,获取初始网页的URL并排队,直到系统定义的关闭条件,例如命名空间。或网站分析级别已完成。实际应用程序中,生成的URL主要表示为绝对地址和相对地址。定且明确的Internet资源的位置(包括域名(主机名),路径和文件名)称为绝对地址。相对地址只是绝对地址的一部分。得的信息包括页面标题,内容,链接,分析时间等,信息通过系统程序的算法过滤并存储在数据库中。序计算后删除HTML,Javascript和其他过多的冗余信息。果未处理,则搜索将不准确。果您希望机器人继续工作,则必须分析页面上的其他URL。必须使用常规从页面中提取所有URL并将它们放入队列中。样,多线程技术继续按队列顺序扫描网页。Lucene提供了五个基本类,Document,Field,IndexWriter,Analyzer和Directory,用于索引文档。Document对象由多个Field对象组成。
档用于描述该类型的文档,包括HTML页面,电子邮件或文本文件。果使用数据库记录来理解每个Document对象,则每个Zone对象都是记录的相应字段。
Analyzer类是一个具有多个实现的抽象类。
索引文档之前,必须通过Analyzer进行分词处理。可以为不同的语言和应用选择合适的分析仪。Analyzer将分词的内容传递给IndexWriter以进行索引。户友好的查询是所有搜索引擎的目标。查询页面上输入关键字后,将其提交给系统,该系统由程序处理并显示为列表。Lucene搜索引擎中,您必须使用Lucene提供的方法来获取您创建的索引文件的结果。置Web Robot时,会在“控制面板”中输入有效的URL。后,URL用于根据级别浏览相关链接,然后通过这些连接存储在网页数据库中,然后是索引生成程序。取,为每条记录生成索引记录,并将其存储在生成的索引库文件中。成索引需要调用Lucene.Net类。成索引后,您可以直接在查询页面上输入关键字,查询系统生成的索引库,并返回信息。还可以查明信息来源。束语在这个互联网泡沫快速扩张的时代,网络拥有数亿个网页,人类收集和组织网页的工作量极其难以想象。果,智能搜索用于通过网络收集网页数据,并且系统创建索引数据库而不是大而不可能的手动操作。用户浏览网页并需要搜索相关内容时,他通过选择关键字来搜索关键字。能搜索引擎应该显示包含用户和程序的关键字的所有网页。
须基于存储在索引数据库中的术语。键字的相关性已排序。过程需要一系列复杂的算法来执行大量计算,以便在评论网页上显示用户的必要信息,以便用户可以快速获得搜索结果。
本文转载自
宁波网站优化www.leseo.net
补充词条:
宁波网站seo优化
宁波seo外包
宁波网络seo公司
宁波网站优化推广
宁波seo排名


