随着数字校园的快速发展,搜索引擎技术得到了广泛的应用,Web数据挖掘已成为一种数据挖掘技术。索引擎是基于Web上数据探索的重要研究重点。
园网络上的信息每天都在以不可估量的速度增长。

千上万的网络资源使教师和学生在广阔的信息海洋中熠熠生辉,搜索引擎看起来非常好。
决了这个真正的问题。Web数据挖掘可以从教师和学生感兴趣的大量Web文档和Web页面中提取潜在的和隐藏的信息,并为校园网络的搜索引擎系统提供强大的技术支持。Web数据挖掘技术随着信息时代的飞速发展,Internet已成为人们获取信息的重要手段。络作为一个信息资源平台,为人们的日常生活提供方便快捷的服务。
而,面对网络上的大量信息,如何不被淹没,如何及时从大量信息中提取有价值的信息,已成为在互联网上查找信息的主要问题。对这一挑战,Web挖掘技术提供了更好的解决方案。Web数据挖掘技术包括使用许多技术的数据库技术,计算机网络和人工智能技术,但它不是传统Data Min技术的简单应用。是一个新的研究领域。Web挖掘技术通常分为三类:Web结构挖掘,Web内容挖掘和Web日志挖掘。Web内容挖掘是指使用某些算法策略来提取网络资源以发现有用的知识,例如摘要,分类,分类和关联分析。部网页结构和外部结构的提取(链接分析)是网络结构探索的两个主要搜索轴:内部结构提取适用于信息检索,网站结构模板提取和页面分类。Web日志挖掘的目的是通过识别用户的浏览模式和改进网站结构来吸引更多用户访问网站,使导航更加方便。Web数据挖掘与搜索引擎密切相关。了使用传统的搜索引擎理论和技术方法外,校园搜索引擎还需要新的方法和技术来满足教师和学生的需求。多Web数据挖掘技术可以应用于校园。Web搜索引擎中,Web内容爬行可以汇总,分类,分组,关联和预测Internet网页信息中的趋势。过利用网页的内容,可以对网页进行分组和分类,对网络信息进行分类,浏览和提取,从而提高网络信息的索引准确性和网络效率。复。据数据挖掘和相关理论的一般方法,您可以获得Web数据挖掘流程图,如图1所示。络数据收集的主要目的是从中提取数据的子集从网站信息,包括页面数据,超链接信息和用户访问历史记录等,为数据挖掘提供资源支持。
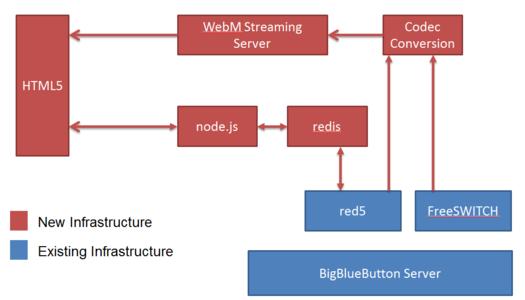
据预处理主要用于组织和重建数据源,并创建主题数据库,为Web数据挖掘提供相应的平台。型发现和分析是Web数据挖掘的重要组成部分,它主要使用潜在的数据挖掘技术从数据对象中发现潜在的,可理解的知识模式,最后发现描述性和预测性模型。园网搜索引擎网络体系结构设计模式框架模型总体设计校园网搜索引擎系统设计,智能化目标,最大限度地满足师生的不同需求。统首先在网页上收集大量信息,然后搜索引擎程序自动分析收集的网页的内容,并通过分词程序获得句子关键词。然后使用索引创建索引数据库。用户通过网页查询索引数据库时,系统返回与搜索关键字对应的所有网页。索引擎系统主要由以下四个部分组成:页面收集模块,页面分析模块,索引数据库模块和信息搜索模块。功能上,内容的四个部分彼此独立并且彼此相关以形成有机整体。索引擎的系统架构如图2所示。统模块设计本文档设计的校园网搜索引擎系统与传统搜索引擎系统的主要区别在于搜索引擎被分解为几个具有不同任务的专业搜索引擎。个专业搜索引擎只查找特定信息。索引擎系统主要由五个模块组成。息捕获模块:搜索引擎系统首先收集用户和搜索引擎返回的查询结果,然后预处理收集的数据。念提取模块:系统从收集的搜索结果中选择前100个数据,提取概念,并将提取的概念存储在相应的数据库中。后,搜索引擎系统计算概念连接并将计算结果存储在数据库中,以便准备随后的概念聚类。户建模模块:系统从用户的搜索关键词中提取概念以获得用户感兴趣的相关概念,然后基于用户的搜索关键词确定与其相关的概念。立了概念链接。询概念聚类模块:系统基于用户兴趣模型建立二分查询概念图,然后使用基于查询概念的二分图聚类算法对查询进行聚类。个概念分别是。询优化模块:对类似查询和类似概念进行聚类可优化查询语句,查询语句由Search Appliance提交给搜索系统。用户提供类似的概念作为搜索建议,并且系统基于用户的兴趣模型生成分组结果。于网络的数据挖掘技术在数字校园中的应用主要依赖于参与建设数字校园的教师和学生。调师生关系的最佳方式是数据挖掘的首要考虑因素。文档通过处理学校每个子图书馆的个人信息,将学生数字校园的基本信息作为基本信息,
宁波seo并使用简单的统计方法汇总每个子图书馆的信息。获取数据挖掘所需的基本信息。
索引擎系统必须首先将不同的数据源集中在统一的数据仓库中,以执行数据清理和转换操作。了促进不同数据仓库之间的数据交换,采用统一的数据挖掘元数据模型。Web数据提取技术使用统一的驱动程序来访问数据仓库数据,并使用结果模型的统一表示。用程序通过统一接口访问数据挖掘服务。据挖掘应用程序体系结构如图3所示,其中Data表示要提取的数据并存储在数据库或关系文件中。
据访问从文件,数据库或视图中检索数据并将其保存到数据仓库。据源可以来自分布式和远程数据库。据仓库用于存储要提取的数据,驱动程序提供统一的数据库驱动程序,DMT为应用程序提供不同的算法。据挖掘(DMM)应用在数据上获得的结果。同的DMT可以称为数据挖掘模型,用于结果的应用,评估和可视化。用程序是一个客户端应用程序,它调用一个或多个数据挖掘服务来获取数据挖掘的结果模型,以获取决策所需的信息。Web数据挖掘中,应用程序相关性分析技术用于搜索网页信息数据库中值的相关性,并且分类方法允许分析Web数据。页信息数据库,以便允许建立数据模型和提取每个类别的分类规则。
此,准确地描述了数据类别,并且应用分组方法来分析网页信息库中的记录数据,即记录集是合理的计划并确定每条记录的类别。过这种方式,可以改进具有高集成度,易于使用和冗余的索引数据库,以便于教师和学生进行信息检索和信息检索。束语基于Web的数据挖掘技术是一个新兴的研究领域,具有很大的发展潜力。
过多次研究,她取得了一定的成果,在校园网搜索系统的应用中发挥了重要作用。于Web的数据挖掘技术在校园数字化建设中的普及需要大量的工作,需要进一步探索。者:天津大学信息技术学院专业技术教育学院"
本文转载自
宁波seowww.leseo.net
补充词条:
宁波网站seo优化
宁波seo排名
宁波网站seo
宁波seo优化公司
宁波网站优化推广


